Работа с семантическим ядром на практике. Как использовать семантическое ядро. Как составить эффективное семантическое ядро самостоятельно Семантическое ядро и целевые страницы
В данный момент для поискового продвижения максимально важную роль играют такие факторы как контент и структура. Однако, каким образом понять о чем писать текст, какие разделы и страницы создать на сайте? В дополнении к этому вам нужно точно узнать чем именно интересуется целевой посетитель вашего ресурса. Чтобы ответить на все эти вопросы нужно собрать семантическое ядро.
Семантическое ядро — список слов или фраз, полностью отражающих тематику вашего сайта.
В статье я расскажу как его подобрать, почистить и разбить на структуру. Результатом будет являться законченная структура с запросами кластеризованными по страницам.
Вот пример ядра запросов разбитого на структуру:

Под кластеризацией я понимаю разбивку ваших поисковых запросов на отдельные страницы. Данный способ будет актуален как для продвижения в ПС Яндекса, так и Гугла. В статье я опишу совершенно бесплатный способ создания семантического ядра, однако буду показывать и варианты с различными платными сервисами.
Прочитав статью, вы научитесь
- Выбирать правильные запросы под вашу тематику
- Собирать максимально полное ядро фраз
- Чистить от неинтересных запросов
- Группировать и создавать структуру
Собрав семантическое ядро вы сможете
- Создать осмысленную структуру на сайте
- Создать многоуровневое меню
- Наполнять страницы текстами и писать на них метаописания и title
- Собирать позиции вашего сайта по запросам из поисковых систем
Сбор и кластеризация семантического ядра
Правильное составление для Google и Яндекс начинается с определения основных ключевых фраз вашей тематики. Для примера, я буду демонстрировать его составление на выдуманном интернет-магазине одежды. Есть три пути по сбору семантического ядра:
- Ручной.
Используя сервис Яндекс Wordstat , вы вводите ваши ключевые слова и руками выбираете необходимые вам фразы. Данный способ достаточно быстрый, если вам нужно собрать ключи на одну страницу, однако, есть два минуса.
- Точность метода «хромает». Вы всегда можете упустить какие-либо важные слова, если будете использовать этот метод.
- Вы не сможете собрать семантическое ядро на большой интернет-магазин, хотя для упрощения можно использовать плагин Yandex Wordstat Assistant — проблему это не решит.
- Полуавтоматический.
В этом методе я предполагаю использование программы для сбора ядра и дальнейшее ручная разбивка на разделы, подразделы, страницы и т.п. Данный метод составления и кластеризации семантического ядра по моему мнению наиболее эффективный т.к. имеет ряд плюсов:
- Максимальный охват всей тематики.
- Качественная разбивка
- Автоматический. В наше время существует несколько сервисов, которые предлагают полностью автоматический сбор ядра либо же кластеризацию ваших запросов. Полностью автоматический вариант — не рекомендую к использованию, т.к. качество сбора и кластеризации семантического ядра на данный момент довольно низкая. Автоматическая кластеризация запросов — набирает популярность и имеет место быть, но вам необходимо все-равно будет объединять какие-то страницы руками, т.к. система не дает идеального готового решения. И по моему мнению вы просто запутаетесь и не сможете погрузиться в проект.
Для составления и кластеризации полноценного правильного семантического ядра на любой проект в 90% случаев я использую полуавтоматический метод.
Итак, чтобы нам нужно выполнить следующие шаги:
- Подбор запросов для тематики
- Сбор ядра по запросов
- Чистка от нецелевых запросов
- Кластеризация (разбиваем фразы на структуру)
Пример подбора семантического ядра и группировки на структуру я показывал выше. Напоминаю, что у нас интернет-магазин одежды, начнем же разбирать 1 пункт.
1. Подбор фраз для вашей тематики
На данном этапе нам понадобиться инструмент Яндекс Вордстат , ваши конкуренты и логика. В этом шаге важно собрать список фраз, которые являются тематическими высокочастотными запросами.
Как подбирать запросы для сбора семантики с Yandex Wordstat
Заходите на сервис, выбираете нужный вам город(а)/регион(ы), вбиваете самые «жирные» по вашему мнению запросы и смотрите на правую колонку. Там вы найдете нужные вам тематические слова, как на другие разделы, так и частотные синонимы к вписанной фразе.

Как подбирать запросы перед составлением семантического ядра с помощью конкурентов
Впишите в поисковой системе самый популярные запросы и выберите один из самых популярных сайтов, многие из которых вы, скорее всего, и так знаете.

Обратите внимание на основные разделы и сохраняйте себе необходимые вам фразы.
На данном этапе важно сделать правильно: максимально охватить всевозможные слова из вашей тематики и ничего не упустить, тогда ваше семантическое ядро будет максимально полным.
Применимо к нашему примеру, нам нужно составить список из следующие фраз/ключевых слов:
- Одежда
- Обувь
- Сапоги
- Платья
- Футболки
- Нижнее белье
- Шорты
Какие фразы вписывать бессмысленно : женская одежда, купить обувь, платье на выпускной и т.п. Почему? — Данные фразы являются «хвостами» запросов «одежда», «обувь», «платья» и будут добавлены в семантическое ядро автоматически на 2 этапе сбора. Т.е. вы можете их добавлять, но это будет бессмысленной двойной работой.
Какие ключи вписывать нужно? «полусапоги», «сапожки» не одно и тоже, что и «сапоги». Важна именно словоформа, а не то однокоренные это слова или нет.
У кого-то список ключевых фраз будет длинный, а у кого он состоит из одного слова — не пугайтесь. Например, интернет-магазину дверей для составления семантического ядра вполне возможно достаточно слова «двери».
И так, в конце данного шага у нас должен быть подобный список.

2. Сбор запросов для семантического ядра
Для правильного полноценного сбора нам необходимо программа. Я буду показывать пример одновременно на двух программах:
- На платной — KeyCollector. Для тех у кого есть, либо кто хочет купить.
- На бесплатной — Slovoeb. Бесплатная программа для тех, кто не готов тратиться.
Открываем программу

Создаем новый проект и назовем его, например, Mysite

Теперь для дальнейшего сбора семантического ядра нам нужно сделать несколько вещей:
Создать новый аккаунт на Яндекс почте (старый не рекомендуется использовать по причине того, что его могут забанить за множество запросов). Итак, вы создали аккаунт, например [email protected] с паролем super2018. Теперь вам нужно указать этот аккаунт в настройках как ivan.ivanov:super2018 и нажать внизу кнопку «сохранить изменения». Подробнее — на скриншотах.

Выбираем регион для составления семантического ядра. Нужно выбрать только те регионы, в которых вы собираетесь продвигаться и нажать сохранить. От этого будет зависеть частотность запросов и попадут ли они в сбор в принципе.

Все настройки завершены, осталось добавить наш заготовленный на первом шаге список ключевых фраз и нажать кнопку «начать сбор» семантического ядра.

Процесс полностью автоматический и достаточно долгий. Можете пока сделать кофе, а если тематика широкая, например, подобно той, что мы собираем — то это на несколько часов 😉
Как только все фразы соберутся вы увидите нечто подобное:

И на этом этап закончен — приступаем к следующему шагу
3. Чистка семантического ядра
Вначале нам нужно удалить запросы, которые нам не интересны (нецелевые):
- Связанные с другим брендом, например, «глория джинс», «экко»
- Информационные запросы, например, «ношу сапоги», «размер джинсов»
- Схожие по тематике, но не относящиеся к вашему бизнесу, например, «б у одежда», «одежда оптом»
- Запросы, никак не связанные с тематикой, например, «симс платья», «кот в сапогах» (таких запросов после подбора семантическом ядре бывает достаточно много)
- Запросы из других регионов, метро, округов, улиц (неважно по какому региону вы собирали запросы — другой регион все-равно попадается)
Чистку нужно проводить вручную следующим образом:

Вводим слово, нажимаем «Enter», если в нашем созданном семантическом ядре находит именно те фразы что нам нужно, выделяем найденное и нажимаем удалить.
Рекомендую вводить слово не целиком, а используя конструкцию без предлогов и окончаний, т.е. если мы напишем слово «глори», то найдет фразы «купить в глория джинс» и «купить в глории джинс». При написании «глория» — «глории» не было бы найдено.
Таким образом вам нужно пройти по всем пунктам и удалить из семантического ядра ненужные вам запросы. Это может занять значительное время, и, возможно, получится так, что вы удалите большую часть собранных запросов, но результатом будет полноценный чистый и правильный список всевозможных продвигаемых запросов для вашего сайта.
Выгрузите теперь все ваши запросы в excel

Также вы можете массово удалить из семантики нецелевые запросы, при условии, что у вас есть список. Можно это сделать при помощи стоп-слов и это легко сделать для типовой группы слов с городами, метро, улицами. Список таких слов, которыми я пользуюсь вы сможете скачать внизу страницы.
4. Кластеризация семантического ядра
Это самая важная и интересная часть — необходимо разделить наши запросы на страницы и разделы, которые в совокупности создадут структуру вашего сайта. Немного теории — чем руководствоваться при разделении запросов:
- Конкуренты . Вы можете обратить внимание на то, как кластеризовано семантическое ядро у ваших конкурентов из ТОПа и поступать аналогичным образом, по крайней мере с основными разделами. А также смотреть, какие страницы находятся в выдаче по низкочастотным запросам. Например, если вы не уверены «делать или нет» отдельный раздел для запроса «красные кожаные юбки», то вбейте фразу в поисковую систему и посмотрите выдачу. Если в выдаче содержаться ресурсы, где есть такие разделы, значит, имеет смысл сделать отдельную страницу.
- Логика . Всю группировку семантического ядра делайте используя логику: структура должна быть понятна и представлять у вас в голове структурированное дерево страниц с категориями и подкатегориями.
И еще пара советов:
- На страницу не рекомендуется ставить менее 3 запросов.
- Не делайте слишком много уровней вложенности, старайтесь делать так, чтобы их было 3-4 (сайт.ру/категория/подкатегория/под-подкатегория)
- Не делайте длинные URL, если у вас много уровней вложенности при кластеризации семантического ядра, старайтесь сокращать url высоких по иерархии категорий, т.е. вместо «vash-site.ru/zhenskaya-odezhda/palto-dlya-zhenshin/krasnoe-palto» делайте «vash-site.ru/zhenshinam/palto/krasnoe»
Теперь к практике
Кластеризация ядра на примере
Для начала разнесем все запросы по основным категориям. Посмотрев по логике конкурентов — основными категориями для магазина одежды будут являться: мужская одежда, женская одежда, детская одежда, а также куча других категорий, которые не привязаны к полу/возрасту, такие как просто «обувь», «верхняя одежда».
Группируем семантическое ядро это при помощи Excel. Открываем наш файл и действуем:
- Разбиваем на основные разделы
- Берем один раздел и разбиваем его на подразделы
Я покажу на примере одного раздела — мужская одежда и его подраздела. Для того, чтобы отделить одни ключи от других нужно выделить весь лист и нажать условное форматирование->правила выделения ячеек->текст содержит

Теперь в открывшемся окне пишем «муж» и нажимаем энтер.

Теперь все наши ключи по мужской одежде выделены. Достаточно воспользоваться фильтром, чтобы отделить выделенные ключи от всего остального нашего собранного семантического ядра.
Итак включим фильтр: нужно выделить столбик с запросами и нажать сортировка и фильтр->фильтр

И теперь отсортируем

Создайте отдельный лист. Вырезайте выделенные строки и вставляйте их туда. Этим способом вам нужно будет в дальнейшем и разбивать ядро.
Измените название этого листа на «Мужская одежда», лист, где все остальное семантическое ядро назовите «Все запросы». Затем создайте еще один лист, назовите его «Структура» и поставьте его самым первым. На странице со структурой создавайте дерево. У вас должно получится так:

Теперь нам нужно разделить большой раздел мужской одежды на подразделы и под-подразделы.
Для удобства использования и переходов по вашему кластеризованному семантическому ядру поставьте ссылки со структуры на соответствующие листы. Для этого кликните правой кнопкой мыши на нужный пункт в структуре и делайте как на скриншоте.

И теперь методично руками нужно разделять запросы, попутно удаляя то, что, возможно, не удалось заметить и удалить на этапе очистки ядра. В конечном счете благодаря кластеризации семантического ядра у вас должна получится структура похожая на вот эту:


Итак. Что мы научились делать:
- Выбирать нужные нам запросы для сбора семантического ядра
- Собирать все-возможные фразы для этих запросов
- Чистить от «мусора»
- Кластеризовать и создавать структуру
Что благодаря созданию такого кластеризованного семантического ядра вы можете делать дальше:
- Создавать структуру на сайте
- Создавать меню
- Писать тексты, метаописания, тайтлы
- Собирать позиции для отслеживания динамики по запросам
Теперь немного о программах и сервисах
Программы для сбора семантического ядра
Здесь я опишу не только программы, но и плагины и онлайн сервисы, которые использую
- Yandex Wordstat Assistant — плагин, благодаря которому, удобно подбирать запросы из вордстата. Отлично подходит для быстрого составления ядра на маленький сайт или на 1 страницу.
- Кейколлектор (словоеб — бесплатная версия) — полноценная программа для кластеризации и создания семантического ядра. Пользуется большой популярностью. Огромное количество функционала помимо основного направления: Подбор ключей с кучи других систем, возможность автокластеризации, сбор позиций в Яндексе и Гугле и многое другое.
- Just-magic — многофункциональный онлайн-сервис для составления ядра, авторазбивки, проверка качества текстов и также другие функции. Сервис условно-бесплатный, для полноценной работы нужно платить абонентскую плату.
Спасибо за то, что прочитали статью. Благодаря данному пошаговому мануалу вы сможете составить семантическое ядро вашего сайта для продвижения в Яндексе и Гугле. Если у вас остались какие-либо вопросы — задавайте в комментариях. Ниже — бонусы.
2014 год в сфере поисковой оптимизации выявил новый тренд - продумывание и сборка семантического ядра. СЯ представляет собой обширный перечень для сайта ключевых запросов, и при его сборке преследуются следующие цели:
Обнаружить значительное количество НЧ/мНЧ вхождений
Обнаружить минимально конкурентные запросы
Максимально охватить ЦА
Разработать структуру сайта или откорректировать уже имеющуюся
Повысить хостовые метрики вебсайта
Составление семантического ядра - непростой процесс, который подразделяется на следующие стадии:
Подготовительный этап
Определение базовых сегментов вебсайта
Увеличение перечня
Оптимизация СЯ
Деление веб-серверов на кластеры
Составление перечня лэндинговых страниц
По итогам в структуру ресурса внедряются запросы. Качественно подобранное СЯ представляет собой проработанный каркас сайта с крупным числом лэндинговых страниц.
Ключевые запросы
При подборе «ключевиков» для СЯ нужно подготовить изначальный перечень сегментов сайта согласно созданной структуре, для чего формируются стартовые вхождения, которые характеризуют сайт. Затем в первичный перечень добавляется детальная информация о товаре или услуге согласно ее характеристикам.
Список запросов значительно увеличивается, при этом он содержит только актуальные данные с вебсайта. Комбинации слов из перечная формируют словосочетания, из которых составляется расширенный список первичных запросов.
Расширение перечня запросов
Ключевиков, выработанных этим методом, не хватает, ведь не учитываются пользовательские фразы из поисковых систем. Расширить список запросов можно с помощью сервисов вроде wordstat.yandex.ru, подсказок поисковых систем.
Увеличить список также помогают программы, например KeyCollector.
При подборе данных по спискам вхождений требуется обозначить зону поиска - регион. В дополнение можно узнать и провести анализ продвигаемых конкурентами «ключевиков». Для этого необходимо действовать по алгоритму:
По расширенному перечню первичных запросов определить сайты-конкуренты. В этом помогут специальные сервисы, среди которых www.engine.seointellect.ru/requests_analyses
Проверить результаты на их видимость поисковыми системами и учесть данные в будущем. Примеры подобных сервисов: www.megaindex.ru/?tab=siteAnalyze , www.spywords.ru .
Консолидировать результаты.
Оптимизация СЯ
Сводный файл требует чистки от лишних для сайта вхождений: упоминаний товаров и услуг, отсутствующих на вебсайте, запросов с наименованиями конкурентов и регионами, где товар не распространяется. Все неподходящие запросы необходимо удалить.
Очистить семантическое ядро можно с помощью двух способов.
«Анализ групп» в Key Collector
При запуске Key Collector отобразится список слов и частота их упоминаний в выбранных запросах. Отметьте все неподходящие слова, фразы с упоминанием отмеченных слов выделятся в списке, удалите все лишние вхождения.
Так удатся подчистить СЯ от большей части неподходящих вхождений, но на этом подготовка не заканчивается. Нередко становится нужно убрать часть запросов по выбранному признаку: упоминанию города, региона, определенным вхождениями. Поэтому вам необходимо составить перечень стоп-слов.
Список стоп-слов
Списки стоп-слов подразделяются на общие и специальные. Общие включают запросы по географическому признаку: город, район, регион. То есть, при распространении товара или услуги в регионе, необходимо исключить все запросы с упоминанием регионов в вашем СЯ. Если ваш сайт занимается продажей товара от 10 компаний, то запросы с упоминанием остальных необходимо удалить. Эти стоп-слова определяются при просмотре списка запросов.
Создание списка стоп-слов - дело кропотливое. Упростить себе жизнь можно двумя методами:
Инструмент «Фильтр» в MS Excel
Кнопка «Стоп-слова» в Key Collector
После оптимизации ядра список дополняется нужными вхождениями. Необходимо установить эффективность конкретных запросов для привлечения пользовательского трафика и их перспективность.
Подготовка СЯ
Для дальнейшей работы над семантическим ядром необходимо подобрать дополнительную информацию по запросам.
Вам понадобится установить обычную и точную частотности при вводе запроса. Сначала определим термины. Обычная частота - это числовой показатель количества ввода запросов, включающих необходимый, в поисковую систему в любой морфологической форме.
Точная частота же напротив - это число запросов в точной словоформе. У запроса «семантическое ядро» обычная частота - 8381, а точная - 1202. То есть, дословный запрос без других слов и изменений был введен юзерами 1202 раза за месяц, а с дополнениями - 8381 раз, из чего делаем вывод: эффективное продвижение только по точному запросу невозможно.
Геозависимость
Что такое геозависимость запроса? Геозависимыми называют запросы, результат поисковой выдачи которых различается в зависимости от региона. SEO-специалисты нередко обращаются к запросам с геозависимостью, присваивая нужные регионы конкретному сайту.
Коэффициент эффективности запроса
Все необходимые цифры для расчетов могут быть получены с помощью программы Key Collector. Следующий шаг - расчет коэффициента эффективности (КЭ) вхождения при привлечении пользователей на сайт. Рассчитать его можно с помощью следующей формулы:
Коэффициент эффективности (%) = WS«!» * 100 / WS
В данном случае, WS – это обычная частота по wordstat.yandex.ru, а WS«!» – точная частота.
Рассмотрим конкретный расчет КЭ по вхождениям «семантическое ядро» и «создать семантическое ядро»:·
Запрос «семантическое ядро»: WS – 8381, WS«!» – 1202, КЭ = 14,34%
Запрос «создать семантическое ядро»: WS – 242 WS«!» – 14, КЭ = 5,78%

Низкий КЭ не значит, что запрос не нуждается в продвижении, но прежде всего стоит сконцентрироваться на наиболее эффективных запросах. В основном, высокий КЭ именно у низкочастотных запросов, то есть конверсия непопулярных запросов выше.
При создании СЯ стоит сначала сконцентрироваться на геозависимых вопросах, а потом переходить к остальным.
Заключение
Обработанные данные формируют семантическое ядро в виде списка с характеристиками запросов. СЯ распределяется по сегментам сайта, а также по параметрам запросов. Проработанное СЯ - это фундамент для продвижения вебсайта в интернете.
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Семантическое ядро сайта – это полный набор ключевых слов, соответствующих тематике веб-ресурса, по которым пользователи смогут найти его в поисковой системе.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
К примеру, сказочный персонаж баба Яга будет иметь следующее семантическое ядро: баба Яга, баба Яга сказки, баба Яга русские сказки, баба со ступой сказки, баба со ступой и метлой, злая баба волшебница, баба избушка курьи ножки и т.д.
Для чего сайту семантическое ядро
Перед началом работ по продвижению вам необходимо найти все ключи, по которым его могут искать целевые посетители. На основании семантики составляется структура, распределяются ключи, прописываются метатеги, заголовки документов, описания к изображениям, а также разрабатывается анкор-лист для работы со ссылочной массой.
При составлении семантики необходимо решить главную проблему: определить, какую информацию следует опубликовать, чтобы привлечь потенциального клиента.
Составление списка ключей решает еще одну важную задачу: для каждой поисковой фразы вы определяете релевантную страницу, которая полно сможет ответить на вопрос пользователя.
Данная задача решается двумя путями:
- Вы создаете структуру сайта на основе семантического ядра.
- Вы распределяете подобранные термины по готовой структуре ресурса.
Виды ключевых запросов (КЗ) по количеству просмотров
- НЧ – низкочастотные. До 100 показов в месяц.
- СЧ – среднечастотные. От 101 до 1 000 показов.
- ВЧ – высокочастотные. Более 1000 показов.
По статистике, 60-80% всех фраз и слов относятся к НЧ. Работать при продвижении с ними дешевле и проще. Поэтому вы должны составить максимально объемное ядро фраз, которое будет постоянно дополняться новыми НЧ. ВЧ и СЧ также не стоит игнорировать, но основной упор делайте на расширение списка низкочастотников.
Виды КЗ по типу поиска
- Информационные нужны при поиске информации. «Как жарить картофель» или «сколько звезд на небе».
- Транзакционные используются для совершения действия. «Заказать пуховый платок», «скачать песни Высоцкого»
- Навигационные используются для поиска связанного с какой-то конкретной фирмой или привязкой к сайту. «Хлебопечь МВидео» или «смартфоны Связной».
- Прочие - расширенный список, по которому невозможно понять конечную цель поиска. К примеру, запрос «торт Наполеон» – возможно, человек ищет рецепт его приготовления, а, возможно, хочет купить торт.
Как составить семантику
Необходимо выделить главные термины вашего бизнеса и нужд пользователей. К примеру, клиенты прачечной интересуются стиркой и чисткой.
Затем следует определить хвосты и спецификацию (более 2 слов в запросе), которые пользователи добавляют к главным терминам. Этим вы увеличите охват целевой аудитории и снизите частотность терминов (стирка пледов, стирка курток и т.п.).
Сбор семантического ядра вручную
Яндекс Wordstat
- Выберите регион веб-ресурса.
- Введите ключевую фразу. Сервис выдаст вам количество запросов с данным ключевиком за последний месяц и список «родственных» терминов, которые интересовали посетителей. Имейте ввиду, что если вы вводите, к примеру, «купить окна», то получаете результаты по точному вхождению ключевика. Если вводите данный ключ без кавычек, то получаете общие результаты, и запросы типа «купить окна в воронеже» и «купить окно пластиковое» также будут отражены в данной цифре. Для сужения и уточнения показателя можно воспользоваться оператором «!», который ставится перед каждым словом: !купить!окна. Вы получите число, показывающее точную выдачу по каждому слову. Получится список типа: купить пластиковые окна, купить и заказать окна, при этом слова «купить» и «окна» будут отражаться в неизменном виде. Для получения абсолютного показателя по запросу «купить окна» следует применять следующую схему: вводим в кавычках «!купить!окна». Вы получите самые точные данные.
- Соберите слова из левой колонки и проанализируйте каждое из них. Составьте начальную семантику. Обращайте внимание на правую колонку, содержащую КЗ, которые пользователи вводили до или после поиска слов из левой колонки. Вы найдете еще немало нужных фраз.
- Пройдите по вкладке «История запросов». На графике вы сможете проанализировать сезонность, популярность фраз в каждом месяце. Неплохие результаты дает работа с поисковыми подсказками Яндекса. Каждый КЗ вводится в поисковое поле, и на основе всплывающих подсказок расширяется семантика.
Google-планировщик КЗ
- Введите главный ВЧ запрос.
- Выберите «Получить варианты».
- Отберите самые релевантные варианты.
- Повторите данной действие с каждой отобранной фразой.
Изучение сайтов-конкурентов
Используйте этот метод как дополнительный, чтобы определить правильность выбора того или иного КЗ. В этом вам помогут инструменты BuzzSumo, Searchmetrics, SEMRush, Адвсе.
Программы для составления семантического ядра
Рассмотрим некоторые самые популярные сервисы.
- Key Collector. Если вы составляете очень объемную семантику, то без этого инструмента вам не обойтись. Программа подбирает семантику, обращаясь к Яндекс Wordstat, собирает поисковые подсказки данного поисковика, фильтрует КЗ со стоп-словами, очень низкой частотой, дублированные, определяет сезонность фраз, изучает статистику счетчиков и соцсетей, подбирает релевантные страницы к каждому запросу.
- SlovoEB. Бесплатный сервис от Key Collector. Инструмент подбирает ключевые слова, группирует и анализирует их.
- Allsubmitter. Помогает подобрать КЗ, показывает сайты-конкуренты.
- KeySO. Анализирует видимость веб-ресурса, его конкурентов и помогает в составлении СЯ.
Что нужно учитывать при подборе ключевых фраз
- Показатели частотности.
- Большая часть КЗ должна быть НЧ, остальные - СЧ и ВЧ.
- Релевантные поисковым запросам страницы.
- Конкурентов в ТОП.
- Конкурентность фразы.
- Прогнозируемое количество переходов.
- Сезонность и геозависимость.
- КЗ с ошибками.
- Ассоциативные ключи.
Правильное семантическое ядро
Прежде всего, необходимо определиться с понятиями «ключевые слова», «ключи», «ключевые или поисковые запросы» – это слова или фразы, при помощи которых потенциальные клиенты вашего сайта ищут необходимую информацию.
Составьте следующие списки: категории товаров или услуг (далее -ТУ), названия ТУ их бренды, коммерческие хвосты («купить», «заказать» и т.п.), синонимы, транслитерацию на латинице (или на русском соответственно), профессиональные жаргонизмы («клавиатура» – «клава» и т.п.), технические характеристики, слова с возможными опечатками и ошибками («оренбуржский» вместо «оренбургский» и т.п.), привязки к местности (город, улицы и т.п.).
При работе со списками ориентируйтесь на КЗ из договора по продвижению, структуру веб-ресурса, информацию, прайс-листы, сайты-конкуренты, опыт предшествующего SEO.
Приступайте к подбору семантики путем смешения выбранных на предыдущем шаге словосочетаний, используя ручной метод или при помощи сервисов.
Сформируйте список стоп-слов и удалите неподходящие КЗ.
Сгруппируйте КЗ по релевантным страницам. Под каждый ключ подбирается наиболее релевантная страница или создается новый документ. Желательно данную работу проводить вручную. Для крупных проектов предусмотрены платные сервисы типа Rush Analytics.
Идите от большего к меньшему. Сначала распределите ВЧ по страницам. Затем то же самое проделайте с СЧ. НЧ можно добавить к страницам с распределенными по ним ВЧ и НЧ, а также подобрать для них индивидуальные страницы.
После анализа первых результатов работ мы можем увидеть, что:
- продвигаемый сайт не виден по всем заявленным ключевым словам;
- по КЗ выдаются не те документы, которые вы предполагали релевантными;
- мешает неправильная структура веб-ресурса;
- для некоторых КЗ релевантны несколько веб-страниц;
- не хватает релевантных страниц.
При группировке КЗ работайте со всеми возможными разделами на веб-ресурсе, наполняйте каждую страницу полезной информацией, не создавайте дублированный текст.
Распространенные ошибки при работе с КЗ
- была подобрана только очевидная семантика, без словоформ, синонимов и т.д;
- оптимизатор распределил слишком много КЗ на одну страницу;
- одинаковые КЗ распределены на разные страницы.
При этом ранжирование ухудшается, сайт может быть наказан за переспам, а если у веб-ресурса неправильная структура, то продвигать его будет очень сложно.
Не важно, каким образом вы будете подбирать семантику. При правильном подходе вы получите правильное СЯ, необходимое для успешного продвижения сайта.
Быстрая навигация по этой странице:
Как и практически все другие вебмастеры, я составляю семантическое ядро с помощью программы KeyCollector — это безусловно лучшая программа для составления семантического ядра. Как ей пользоваться — это тема для отдельной статьи, хотя и в Интернете полно информации на этот счет — рекомендую, к примеру, мануал от Дмитрия Сидаша (sidash.ru).
Поскольку поставлен вопрос о примере составления ядра — привожу пример.
Список ключей
Предположим, у нас сайт посвящен британским кошкам. Вбиваю в «Список фраз» словосочетание «британская кошка» и нажимаю на кнопку «Парсить».
Получаю длинный список фраз, который будет начинаться со следующих фраз (приведена фраза и частнотность):
Британские кошки 75553 британские кошки фото 12421 британская вислоухая кошка 7273 питомник британских кошек 5545 кошки британской породы 4763 британская короткошерстная кошка 3571 окрасы британских кошек 3474 британские кошки цена 2461 кошка голубая британская 2302 британская вислоухая кошка фото 2224 вязка британских кошек 1888 британские кошки характер 1394 куплю британскую кошку 1179 британские кошки купить 1179 длинношерстная британская кошка 1083 беременность британской кошки 974 кошка британская шиншилла 969 кошки британской породы фото 953 питомник британских кошек москва 886 окрас британских кошек фото 882 британские кошки уход 855 британская короткошерстная кошка фото 840 шотландские и британские кошки 763 имена британских кошек 762 кошка британская голубая фото 723 фото британской голубой кошки 723 британская кошка черная 699 чем кормить британских кошек 678
Сам список намного больше, я только привел его начало.
Группировка ключей
Исходя из этого списка, у меня на сайте будут статьи про разновидности кошек (вислоухая, голубая, короткошерстная, длинношерстная), будет статья про беременность этих животных, про то, чем их кормить, про имена и так далее по списку.
Под каждую статью берется один основной такой запрос (=тема статьи). Впрочем, только одним запросом статья не исчерпывается — в нее также добавляются другие подходящие по смыслу запросы, а также разные вариации и словоформы основного запроса, которые можно найти в Кей Коллекторе ниже по списку.
Например, со словом «вислоухая» имеются следующие ключи:
Британская вислоухая кошка 7273 британская вислоухая кошка фото 2224 британская вислоухая кошка цена 513 порода кошек британская вислоухая 418 британская голубая вислоухая кошка 224 шотландские вислоухие и британские кошки 190 кошки британской породы вислоухие фото 169 британская вислоухая кошка фото цена 160 британская вислоухая кошка купить 156 британская вислоухая голубая кошка фото 129 британские вислоухие кошки характер 112 британская вислоухая кошка уход 112 вязка британских вислоухих кошек 98 британская короткошерстная вислоухая кошка 83 окрас британских вислоухих кошек 79
Чтобы не было переспама (а переспам может быть и по совокупности использования слишком большого количества ключей в тексте, в заголовке, в и т.д.), я бы не стал брать их все с включением основного запроса, но отдельные слова из них имеет смысл употребить в статье (фото, купить, характер, уход и т.д.) для того, чтобы статья лучше ранжировалась по большому количеству низко-частотных запросов.
Таким образом, у нас под статью про вислоухих кошек сформируется группа ключевых слов, которые мы употребим в статье. Точно также сформируются и группы ключевиков под другие статьи — вот и ответ на вопрос о том, как создать семантическое ядро сайта.
Частотность и конкуренция
Еще есть немаловажный момент, связанный с точной частотностью и конкуренцией — их обязательно нужно собрать в Key Collector. Для этого нужно выделить все запросы галочками и на вкладке «Частотности Yandex.Wordstat» нажать кнопку «Собрать частотности «!» — будет показана точная частнотность каждой фразы (т.е. именно с таким порядком слов и в таком падеже), это намного более точный показатель, чем общая частотность.
Для проверки конкуренции в том же Key Collector нужно нажать кнопку «Получить данные для ПС Яндекс» (или для Google), далее нажать «Рассчитать KEI по имеющимся данным». В результате программа соберет, сколько главных страниц по данному запросу находится в ТОП-10 (чем больше — тем сложнее туда пробиться) и сколько страниц в ТОП-10 содержат такой title (аналогично, чем больше — тем сложнее пробиться в топ).
Дальше нужно действовать исходя из того, какая у нас стратегия. Если мы хотим создать всеобъемлющий сайт про кошек, то нам не так важна точная частотность и конкуренция. Если же нам нужно только опубликовать несколько статей — то берем запросы, у которых самая высокая частотность и при этом самая низкая конкуренция, и на их основании пишем статьи.
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его
вместе!
Небольшое предисловие
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
- мозговой штурм - анализ базовых фраз и подготовка парсинга
- парсинг - расширение базовой семантики на основе Вордстат и других источников
- отсев - отсев после парсинга
- анализ - анализ частотности, сезонности, конкуренции и других важных показателей
- доработка - групировка, разделение коммерческих и информационных фраз ядра
О наиболее важных этапах сбора и пойдет речь ниже!
ВИДЕО - составление семантического ядра по конкурентам
Мозговой штурм при создании семантического ядра — напрягаем мозги
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
- seo блог
- сео блог
- блог про сео
- блог про seo
- продвижение
- продвижение проекта
- раскрутка
- раскрутка
- продвижение блогов
- продвижение блога
- раскрутка блогов
- раскрутка блога
- продвижение статьями
- статейное продвижение
- miralinks
- работа в sape
- покупка ссылок
- закупка ссылок
- оптимизация
- оптимизация страницы
- внутренняя оптимизация
- самостоятельная раскрутка
- как раскрутить ресурс
- как раскрутить свой сайт
- как раскрутить сайт самому
- как раскрутить сайт самостоятельно
- самостоятельная раскрутка
- бесплатная раскрутка
- бесплатное продвижение
- поисковая оптимизация
- как продвинуть сайт в яндексе
- как раскрутить сайт в яндексе
- продвижение под яндекс
- продвижение под гугл
- раскрутка в гугл
- индексация
- ускорение индексации
- выбор донора сайту
- отсев доноров
- раскрутка постовыми
- использование постовых
- раскрутка блогами
- алгоритм яндекса
- апдейт тиц
- апдейт поисковой базы
- апдейт яндекса
- ссылки навсегда
- вечные ссылки
- аренда ссылок
- арендованные ссылке
- ссылки с помесячной оплатой
- составление семантического ядра
- секреты раскрутки
- секреты раскрутки
- тайны seo
- тайны оптимизации
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :
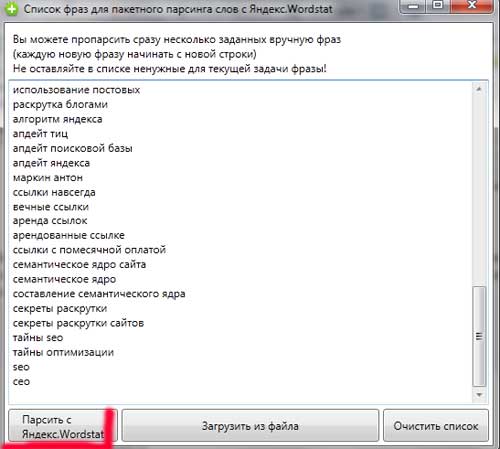
Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Чистка семантики
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:

Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
курсы поисковой оптимизации продам раскрученный сайт
Анализ семантического ядра
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Экспорт и группировка семантического ядра
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:

Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
- такие частотные запросы, как должны иметь намного больший хвост из менее частотных фраз, чем мы видим
- сео новости
- всплыл новый ключ, который мы не учли ранее — статьи сео . Необходимо проанализировать этот ключ
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
- лучший seo блог
- seo новости
- статьи seo
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
Финальный отсев
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:
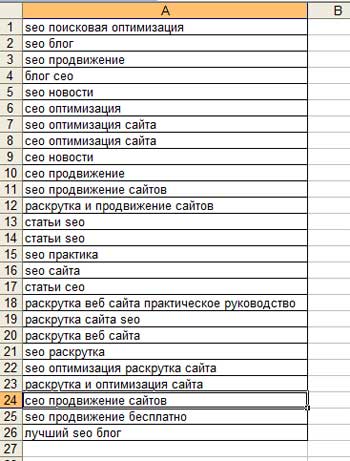

Затем проверяем стоимость получения одного перехода по нашим ключевым словам:

Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.
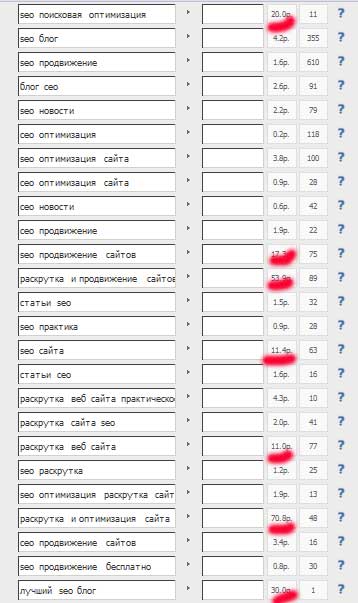
Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
Полезная информация!
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Кластеризация семантического ядра
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
- Подбор и анализ поисковых запросов
- Группировка запросов по страницам сайта (создание посадочных страниц)
- Подготовка seo текстов для посадочных страниц на основе группы запросов для этих страниц
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
- Один и тот же интент могут иметь несколько запросов не имеющих какой-либо семантической близости, например – “обслуживание автомобиля” и “записаться на ТО”
- Запросы, имеющие абсолютную семантическую близость могут содержать в себе кардинально разные интенты, например, хрестоматийная ситуация – “мобильник” и “мобильники”. В одном случае пользователь хочет купить телефон, а в другом посмотреть фильм
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
- Система поочередно вводит все поданные ей запросы в поисковую выдачу и запоминает результаты из ТОП
- После поочередного ввода запросов и сохранения результатов, система ищет пересечения в выдаче. Если один и тот же сайт одним и тем же документом (страница сайта) находится в ТОП сразу по нескольким запросам, то эти запросы теоретически можно объединить в одну группу
- Становится актуальным такой параметр, как сила группировки, который говорит системе, сколько именно должно быть пересечений, чтобы запросы можно было добавить в одну группу. К примеру, сила группировки 2 означает, что в выдаче по 2-м разным запросам должно присутствовать не менее двух пересечений. Говоря еще проще – минимум две страницы двух разных сайтов должны присутствовать одновременно в ТОП по одному и другому запросу. Пример ниже.
- При группировках больших семантики становится актуальна логика связей между запросами, на основе которой выделяют 3 базовых вида кластеризации: soft, middle и hard. О видах кластеризации мы еще поговорим в следующих записях этого дневника
 Меняем программу для открытия файлов в windows по умолчанию
Меняем программу для открытия файлов в windows по умолчанию Почему не загружается вк и браузер не заходит во вконтакте
Почему не загружается вк и браузер не заходит во вконтакте Распиновка USB на материнской плате: что, где и как
Распиновка USB на материнской плате: что, где и как Способы поиска информации в сети
Способы поиска информации в сети Как заблокировать номер телефона, чтобы не звонили
Как заблокировать номер телефона, чтобы не звонили Что делает процессор в играх Что менять видеокарту или процессор
Что делает процессор в играх Что менять видеокарту или процессор Какие разъёмы на материнской плате
Какие разъёмы на материнской плате